

TL;DR Compressing Redshift tables leads to important (~50%) reduction of disk space used and also improves query performance by decreasing I/O. Different encoding procedures are examined. The UNLOAD-TRUNCATE-COPY procedure was chosen. The compressed data were accomodated in a 3-nodes cluster (was 4), with a ~ 200 $/month saving. The COMPROWS option of the COPY command was not found to be important when using automatic compression.
Why
As you can read in the AWS Redshift documentation:
“Compression is a column-level operation that reduces the size of data when it is stored. Compression conserves storage space and reduces the size of data that is read from storage, which reduces the amount of disk I/O and therefore improves query performance.”
As it is not possible to compress already stored data tables/columns, it would be ideal to compress tables by design, i.e. when defining/building the database schema. However, if you can afford some (depending on tables size) downtime, it might be more efficient not to compress columns when defining the database, as Redshift provides commands to calculate, column by column, the best encoding algorithm once tables have already been filled. Some data juggling will then be required to recreate a compressed copy of existing tables.
How
Compressed data can be created in two different ways:
-
Custom: tables data is compressed according to a set of algorithms chosen, one for each column, at table creation. In practice, the encoding algorithms are ingrained in the Data Definition Language (DDL) statements that create the tables. Choosing the right encoding algorithm from scratch is likely to be difficult for the average DBA, thus Redshift provides the ANALYZE COMPRESSION [table name] command to run against an already populated table: its output suggests the best encoding algorithm, column by column.
-
Autocompression: Automatic compression is applied when loading data to an empty table with the COPY command. This very easily assures that each column is created with a correct encoding algorithm the first time data is COPYed into an empty table. You can then start INSERTing new rows to the table, automatically encoded.
To sum up, whichever way you choose to compress data, you need to perform some data juggling with already existing data/tables in order to (re)create encoded tables or finding encoding algorithms.
Here is a rather dull way to do it:
you UNLOAD the table to S3 table, create a new table using the DDL statements of the original table, then COPY (with right command options) the S3 data into the table.
unload('select * from agg_world_tours')
to 's3://bucket/object_dir'
credentials 'aws_access_key_id=ABCDEF; aws_secret_access_key=FEDCBA'
gzipThen you create the new table. You can do it in different ways: the LIKE command is quite handy.
create table import_agg_world_tours (like agg_world_tours);You then COPY the data into the table
copy import_agg_world_tours from
's3://bucket/object_dir'
credentials 'aws_access_key_id=ABCDEF; aws_secret_access_key=FEDCBA'
COMPUPDATE ON
GZIPThe COMPUPDATE ON is key here, as the COPY command provides automatic compression by default when loading on empty tables, but using only none or the raw encoding algorithm.
Switching COMPUPDATE to ON forces Redshift to think a little more and choose more appropriate algorithms. Also, make sure to add the EXPLICIT_IDS option in case the table possesses an IDENTITY column.
You end up with a compressed copy of the original table, that can be used to extract encoding algorithms or used as a replacement for the original table straight away. In the latter case, you could rename the original table to old_table, then rename the new_encoded_table to table and DROP old_table. Alas, it is not that simple as DROPping the original table, though renamed, would require to CASCADE to other objects, i.e. would destroy all the objects that use the to-be-dropped table, for example VIEWS.
The final, robust way chosen to encode a table was therefore to COPY all the data after TRUNCATEing the original table, directly. While you can always simulate, pre-test and back up all your data beforehand, it is always a little uncomfortable to TRUNCATE a 300 GB production table.
Trick (not suggested)
A third way can be used to compress already existing tables in order to avoid downtime, as suggested here:
- Once a proper encoding algorithm is defined for each column, create an encoded copy of each column, fill the new column with the data from the old column, drop the old column, rename the new column with the original name. Something like:
alter table events add column device_id_new integer delta;
update events set device_id_new = device_id;
alter table events drop column device_id;
alter table events rename column device_id_new to device_id;This technique has not been further explored during this work, as considered too bloated and error prone (think about a 100 columns table), however it can be argued that it should be the technique of choice to avoid downtime, since it does not require an explicit stop to writes to the encoding table. It is however doubtful that such a technique would smoothly work on a moderately/heavily written table: stopping DB writing, truncating and populating seems to be a safer route.
What
Tables info can be displayed with amazon-redshfit-utils table_info script. Sort key and statistics columns are omitted (coming post).
The tables to be encoded were chosen amongst the ones that consumed more than ~ 1% of disk space. Here is a pruned table_info.sql run example
| table | rows | mbytes | enc | pct_of_total |
|---|---|---|---|---|
| events | 2204642391 | 299661 | N | 39.29 |
| sessions | 126003060 | 18808 | N | 2.46 |
| transactions | 35795089 | 7376 | N | 0.96 |
Do!
- Stop writing to the table (this depends on your DB clients)
- Get line numbers (use psql redshift admin or the likes)
- Do Backup redshift (always a good practice)
- Unload the table to S3
- TRUNCATE table
- VACUUM table (noop, immediate)
- COPY command
- Check line numbers are ok
- VACUUM table (noop, immediate)
- ANALYZE table
- Start writing to the table
Results
| table name | # records | size (MB) | UNLOAD (t) | COPY (t) | encoded size (MB) |
|---|---|---|---|---|---|
| events | 2,283,718,416 | 311,573 | 1h:03m | 1h:16m | 157,150 |
| sessions | 129,048,295 | 19,288 | 4m:06s | 4m:21s | 11,264 |
| transactions | 36,816,847 | 7,568 | 1m:09s | 2m:20s | 4073 |
The table shows a disk space reduction of ~ 50% for these tables. You can also see how long the export (UNLOAD) and import (COPY) lasted.
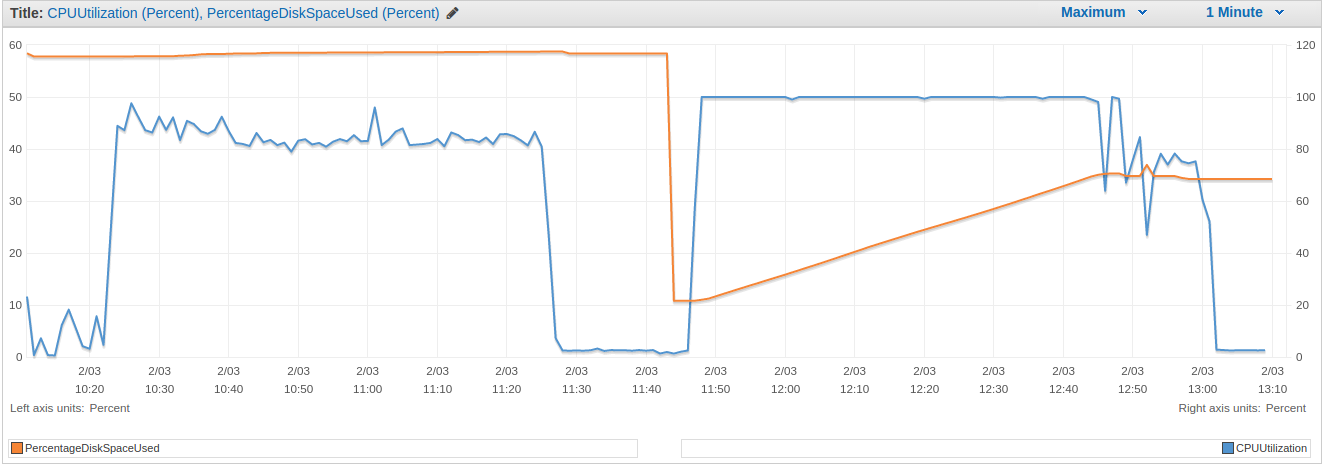
Tables compressions reduced total redshift disk usage from 60% to 35%.
The events table compression (see time plot) was responsible for the majority of this reduction.
As a consequence, a 4-nodes cluster was reduced to 3 (200+ dollars/month saved).
The devil
is in the details.
Redshift performs automatic compression ‘algorithm detection’ by pre-loading COMPROWS number of lines before dumping compressed data to the table. COMPROWS is an option of the COPY command, and it has a default of 100,000 lines.
-
During this study, automatic compression buy loading very big tables from S3 was performed with COMPROWS=10^5 (default), 10^6, 10^7. However, no difference was detected in the encoding algorithm chosen.
-
Interestingly, ANALYZE COMPRESSION [table] run on the events table gave different results for the calculated algorithms by automatic compression, i.e. the events columns have been encoded through automatic compression quite differently then what suggested by ANALYZE.
In any case, the results are so good that further investigation on this topic is waived.