

TL;DR Over time, resources provisioned for different RDS instances might get out of sync with applications demand. It is a very good practice to revise RDS and application metrics periodically to inspect the possibility of downscaling, which can lead to considerable savings without sensibly reducing Quality of Service. The post shows quantitatively how a ~ 12614 dollars reduction in RDS annual bill was achieved.
Generating revenue is arguably the main goal of a private company, however it is quite difficult to contribute to this effort from a pure technical perspective. It is much easier to help companies by reducing costs, which is nonetheless very important. Technical infrastructures are quite expensive, so it is crucial to optimize their usage to reduce cost.
Over time, data streaming in and out of your infrastructure and data processing within your platform can drastically change due to different and disparate reasons. In any case, this has to be reflected into the infrastructure itself, that has to adapt to the changed loads guaranteeing Quality of Service while minimizing costs.
In here, we report the metrics analysis and post-downscaling checks that resulted in an ~ 12614 dollars cost reduction.
From the end
Many RDS instances were resized up or down, but we focus only on two:
- an eu-west-1 multiAZ deployment was modified from r3.2xlarge to m3.xlarge
- a us-west-2 read replica was modified from r3.large to m3.medium
At application level, we used New Relic to make sure that Quality of Service was not degraded significantly, i.e. users would not notice any difference.
The graph below shows the performance of an endpoint after reducing size of the eu-west-1 instance: it is certainly possible to deduce that reduction took place on Thu, Oct 07, 08:32:00 UTC+2, but it is equally easy to conclude that user experience was not appreciably affected.
It is important to stress that, on the plot timescale, downtime cannot be shown, as it only lasted around two minutes.

Preparing the bungee jumping
Scaling down instances type/size without affecting users/application stack is a delicate matter, as it requires to strike a balance between instance price and throughput delivered.
AWS CloudWatch provides a vast set of RDS metrics that can be used to decide resizing details. Collecting metrics is therefore very easy, the difficult thing is to identify redundant/overallocated resources, taking into account that many metrics are not trivially correlated. Additionally, you have to map your conclusions to a discrete set of available RDS instances type/size, i.e. you do not have a lot of choice.
To sum up, reducing RDS production instances is very similar to planning for a bungee jumping installation: you get better every time you do it, with experience, but you are not allowed to fail the first jump.
The following metrics were taken into account:
- CPU/RAM usage
- Read/Write latencies: also, replica lag for replicas.
- Disk queue length and Swap usage
- Read/Write throughput
Finally, after the intervention, application level metrics must confirm that resizing was appropriate (as shown above).
Below, we show the plots of the CloudWatch metrics of the two rescaled instances.
The pattern changes are clearly visible for most of the metrics.
MultiAZ Master
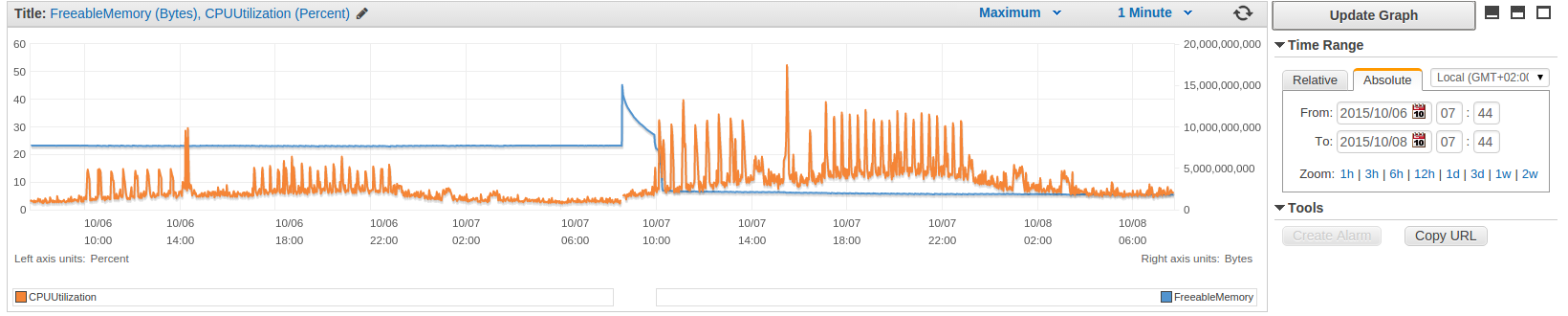

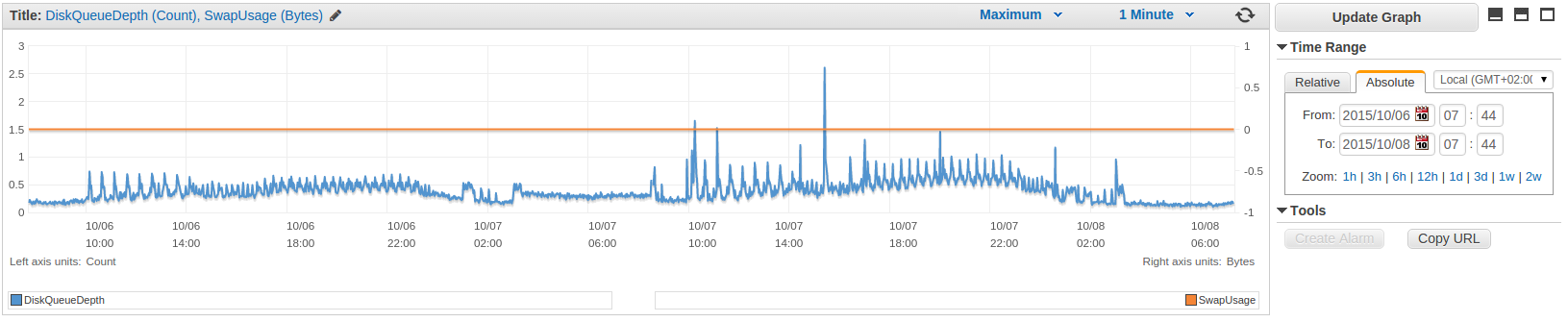

Read Replica

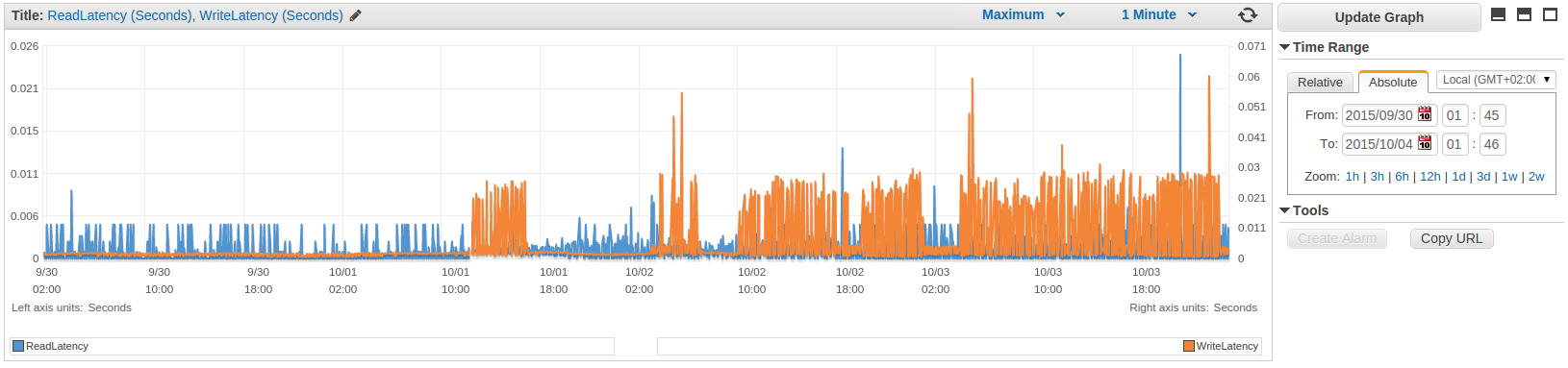
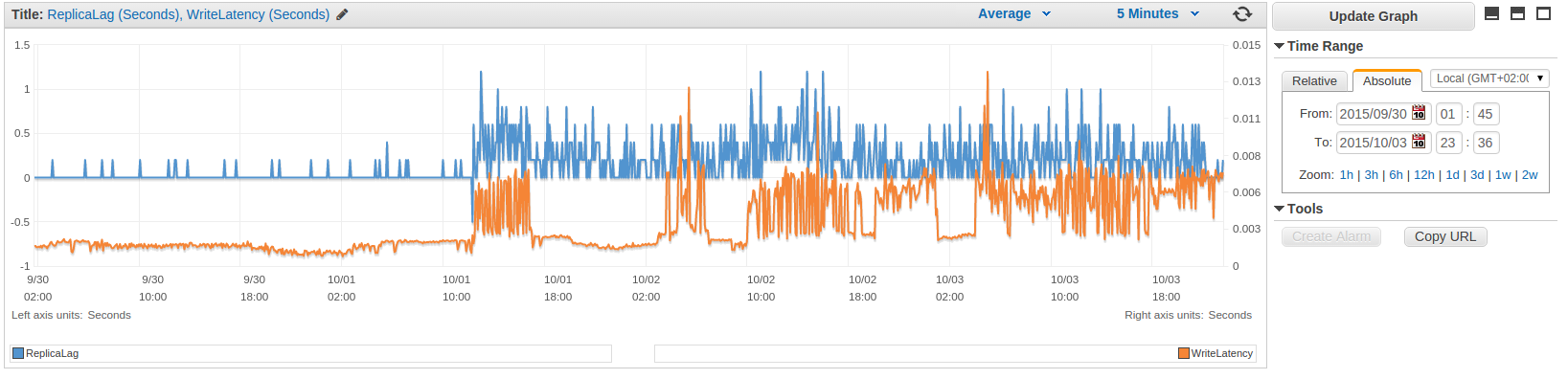


Show me the money!
-
eu-west-1 multiAZ deployment: r3.2xlarge -> m3.xlarge
2.110 $/h * 24 * 30 * 12 ~ 18230 $/y
0.800 $/h * 24 * 30 * 12 ~ 6912 $/y
-
us-west-2 read replica: r3.large -> m3.medium
0.240 $/h * 24 * 30 * 12 ~ 2074 $/y
0.090 $/h * 24 * 30 * 12 ~ 778 $/y
All in all, an annual reduction of ~ 12614 dollars of RDS bill was achieved.